The virtue of laziness
Lunacy is a Lua 5.1 interpreter I’ve been working on as a side-project in Rust. Unlike the average Lua interpreter side-project, Lunacy does type specialization of bytecode operations via Lazy Basic Block Versioning (LBBV), plus includes a Just-in-Time compiler.
LBBV is a pretty cool compilation technique that came out of Maxime Chevalier-Boisvert’s research while at University of Montreal, culminating in her PhD thesis, around developing a JavaScript JIT, Higgs. Critically for me, her approach focuses a lot on simplicity: the goal of LBBV is that it is an effective compilation strategy that can be implemented by just one PhD student in a reasonable amount of time, or one engineer as a side-project.
The original LBBV paper is very approachable, and I highly recommend reading it. To summarize, it enables optimizing bytecode operations, such as ADD, which naively would need to branch on the types of its operands to figure out if it’s adding two numbers or two strings or what have you. Whenever the operation would inspect the type of an operand and check if it matches a type, it can statically be given a pass/fail based on a specialization context for the basic block. If the context doesn’t know the type of the operand, instead of needing to conservatively fall back to a dynamic operation which can handle any value, compilation can instead be suspended to a thunk: the thunk will eventually be forced by execution hitting it at runtime, at which point you can continue compiling with the context now filled with the runtime type of the value promoted to a static type, guarded by a runtime check to validate that later executions of the same codepath use the same type. In the failure case of the guard, you can suspend another thunk that will specialize the operation for the next runtime type you see.
This is very powerful! The end result is that you have blocks which seemingly by magic have type guards only for the types of values that actually were observed at runtime, and for things like loops “for free” unroll one iteration which contains all the type guards, and then have entirely known types inside the hot loop (because that block reached a fixpoint of the specialization context for the loop header, and so reuses the block to form a loop). Because you have the powerful primitive of blocks specialized for a static context based off observed runtime information, you can stuff whatever information in the static context you want and always have a correct “guess” for the value of speculative information. And if you ever end up with too many blocks, no matter what reason, you can fallback to running generic code instead of having exponential block blowup.
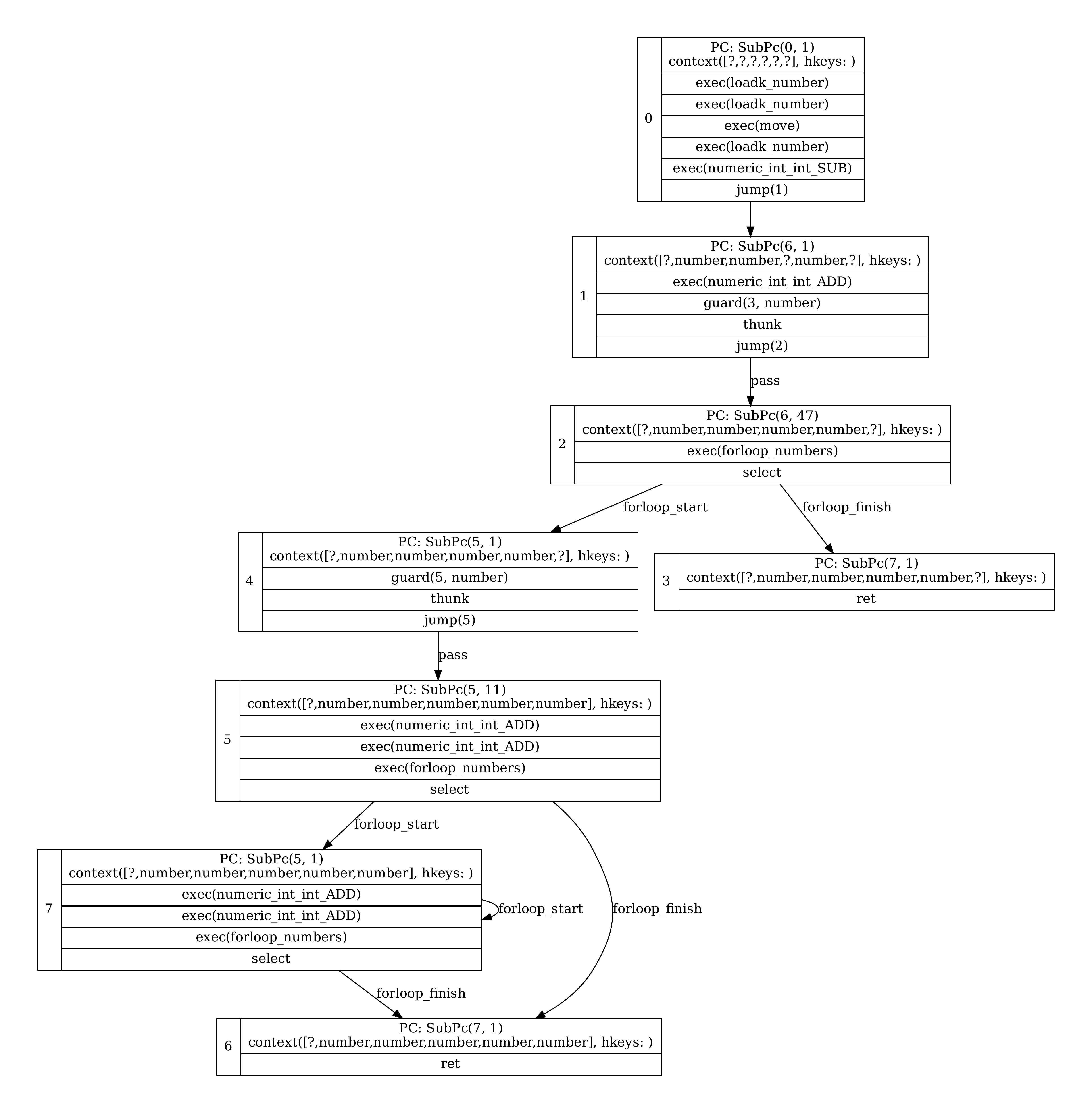
Comparison of Lunacy and Higgs specialized blocks for
sum. Notice how the inner loop body, block7, ends up with fully specializedADDoperations for the accumulator and loop induction variable. Lunacy doesn’t do small-integer optimization and so has no overflow checks.
Lunacy does a few things different from Higgs. For one, Higgs is a pure JIT: it has no interpreter, and immediately compiles all bytecode operations directly to assembly. Lunacy instead is implemented as an interpreter first and a JIT second: bytecode operations are implemented as Rust coroutines, which yield effects. Those effects may be things like “guard on stack slot X being type Y”, which are resumed with results like “the slot matches/fails the guard” - and like LBBV, if the type isn’t currently known, we instead suspend the coroutine inside a thunk via a closure. It may also yield an effect like “add operands A and B together”, which can be implemented so it only cares about how to add numbers since the coroutine would only reach the yield if the required guards matched.
Runtime behavior is emitted as separate residual operations, separate from the actual Lua bytecode operations which are implemented as coroutines that are driven at compile time. In order to avoid having to define and implement runtime behavior for every combination of operand type etc., Lunacy also uses a closure generating interpreter: complex runtime behavior, like adding two numbers, is instead implemented by a closure that captures the bytecode operands such as the stack slot indexes it uses, and at runtime we execute the closure in order to perform the operation. The interpreter repeatedly executes the residual operations that were the result of compiling blocks by running all of the coroutines for the Lua bytecode.
This approach means that the bytecode coroutines in Lunacy were very easy to implement. All of the behavior for an operation, including the different Residual::Exec variants, are located in a single coroutine which intermixes the static compilation portion via yielded effects and the runtime execution portion via closures which can capture arbitrary static information. Because Rust coroutines even implement Clone, when we suspend a coroutine to a thunk in order to discover extra information from the runtime behavior we can even push a clone of the same coroutine suspended at the same yieldpoint down into the failure case - essentially forking it, and each fork independently being resumed to compile the remainder of the operation and block with a different observed type. The interpreter itself is very small and simple, because it only has a small set of simple residual operations to handle.
This residual scheme also made implementing the JIT side of the interpreter very easy as well, which was a large portion of why I chose to use closure generation as well: because our set of residual operations is very small, only things like type guards or executing a closure or executing a thunk (itself also a closure), for the JIT we only need to handle how to compile those same small set of residual operations. Instead of needing to maintain a second assembly implementation for all bytecode operations, we can emit a static call to the closure function pointer address in the JIT, which crucially eliminates dynamic dispatch and other things that make modern OoO processors sad. Meanwhile, the remainder of the residual operations such as runtime typeguards we can implement in assembly in ~4 instructions as a native branch, which also can get their own branch predictor entry. The actual JIT is tiny, and mostly consists of some DynASM-rs assembly in a match.
Because Lunacy is a template JIT where most of our operations are function calls, it doesn’t do any register allocation. It just pins the interpreter state to a register in order to move into the function argument ABI for the closure call repeatedly. However, because the closure call ABI has a number of preserved registers, it does leave open opportunities to do Copy-and-Patch style register windowing using those preserved registers in the future and different residual operations, or use multiple different copies of closures which expect arguments in different registers we can select from during JIT emission.
Unlike Higgs, which immediately JITs all code, we only trigger the JIT after a block hits a hotness threshold because it’s been executed enough times. This means that we will have forced all of the thunks on executed codepaths, unlike Higgs: Lunacy currently doesn’t invalidate or modify JIT code at all, which to me is much easier to reason about, because of this. Because the interpreter and JIT are both running the same residual operations for blocks, bailing out of the JIT back to the interpreter is very easy: the PC for the JIT bailout is the same PC that the interpreter should continue execution at. Thunks which weren’t yet forced when we trigger JIT compilation are handled as bailouts back to the interpreter, which will run the thunk as normal and rewrite it to a jump residual to a new block: if the new block is ran enough jumping to it may end up triggering JIT compilation again. In the future if the JIT->interpreter->JIT transition for thunks ends up being a bottleneck we could fixup the bailout to jump to the newly JIT’d block as well.
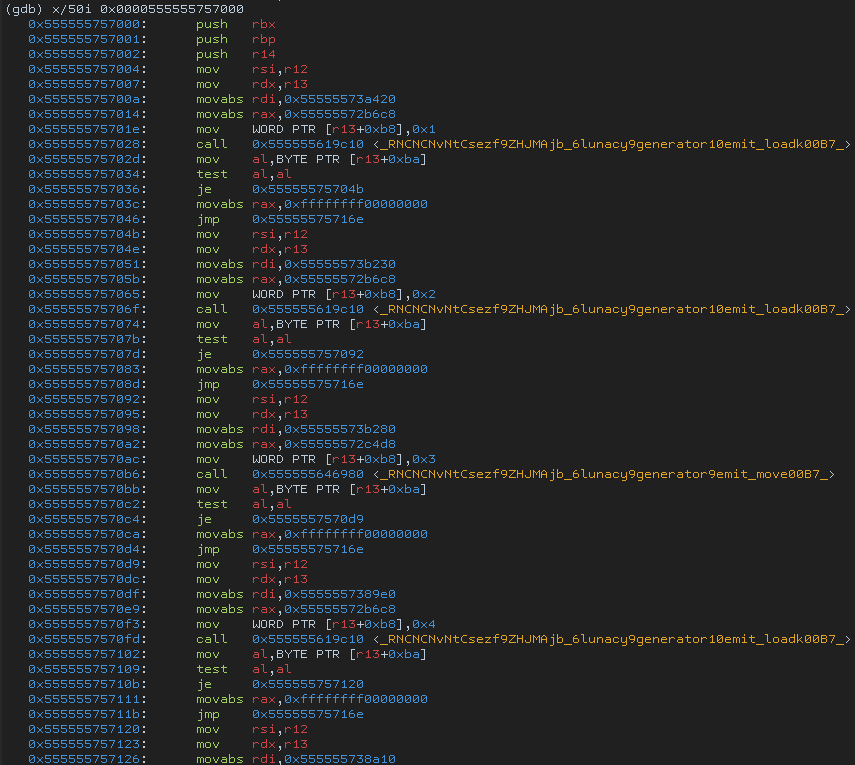
JIT code for
sum. Each residual exec operation turned into a nativeCALLto a static address, with a static closure object pointer. Despite this looking pretty bad for a JIT, it’s still several times faster than the interpreter!
More context
Lunacy doesn’t only specialize the types of stack slots in the specialization context, but also will 1) track the concrete function value for function values 2) specialize table keys to static types and constant offsets.
The first one is fairly basic: just like we can suspend execution in order to discover the runtime type of a value, we can also suspend execution to discover the function pointer of things that we know are functions, again emitting another guard on the pointer value matching our expection. We can do this for both native functions, such as print, as well as Lua functions: this not only lets us in the JIT emit a native call to the C function directly, but also avoid needing to dynamically check the value and switch behavior depending on if its a native call or not, and lets us emit nested calls to more JIT code using the native processor stack instead of the interpreter call stack if the Lua call target is also already JIT’d. Because we can use all of the existing LBBV infrastructure in order to promote dynamic values to static context, this was surprisingly easy to implement.
For two, it was slightly more difficult. V8 implements table specialization in the form of hidden classes with shapes and transition maps: tables are assigned a pointer to a shape, which describes the layout and type of the table, and then at runtime you can emit a shape guard if table.shape != expected: fail; success in order to then emit loads from the table, which result in typed values, at the offset described by the shape in order to avoid hashmap lookups in the JIT. Tables are assigned shapes incrementally based on the order they are built. Code such as
local t = {}
t.a = 1
t.b = 2
would repeatedly transition the shape of the table according to a series of maps saying the next shape for each key that was added, such as
{} -> {a: int} -> {a: int, b: int}
I didn’t want to implement this in Lunacy, however. Because shapes describe the entire layout of a table, it means that any inheritance-like behavior must be compiled as polymorphic blocks: Dog and Cat have different shape pointers, and you could only insert a guard that they are both Animals by implementing more logic that finds the common ancestor and walks shape pointers at runtime, and figuring out when to do that as part of LBBV where all compilation has to progress incrementally (unlike a method or tracing JIT, which looks at multiple blocks at a time upfront) appeared hazardous. Shapes also requires following the transition maps at runtime if you have dynamic keys, and V8 also implements things like shape invalidation which requires being able to migrate JIT stack frames back to the interpreter (which itself necessitate emitting stack maps) to handle some cases.
Because Lua function environments, which contain non-local variables, are themselves tables I would also have the issue of shape pointers transitioning even from unrelated keys potentially invalidating the shape guards for every function just because a new global was added late, requiring a separate scheme to also be added to handle environments.
Instead, Lunacy implements something closer to LuaJIT’s hash slot specialization where the static context only contains the individual keys that are accessed in the block. A function which only accesses properties for an Animal would specialize on the hash slots for those properties being the first discovered type and offset, and for a Dog and Cat which were constructed in the same order for those shared prefix of keys be able to use the same specialized blocks. Likewise, adding a new variable to an environment wouldn’t cause existing guards to fail because the type and offset for all the previous keys stay intact.
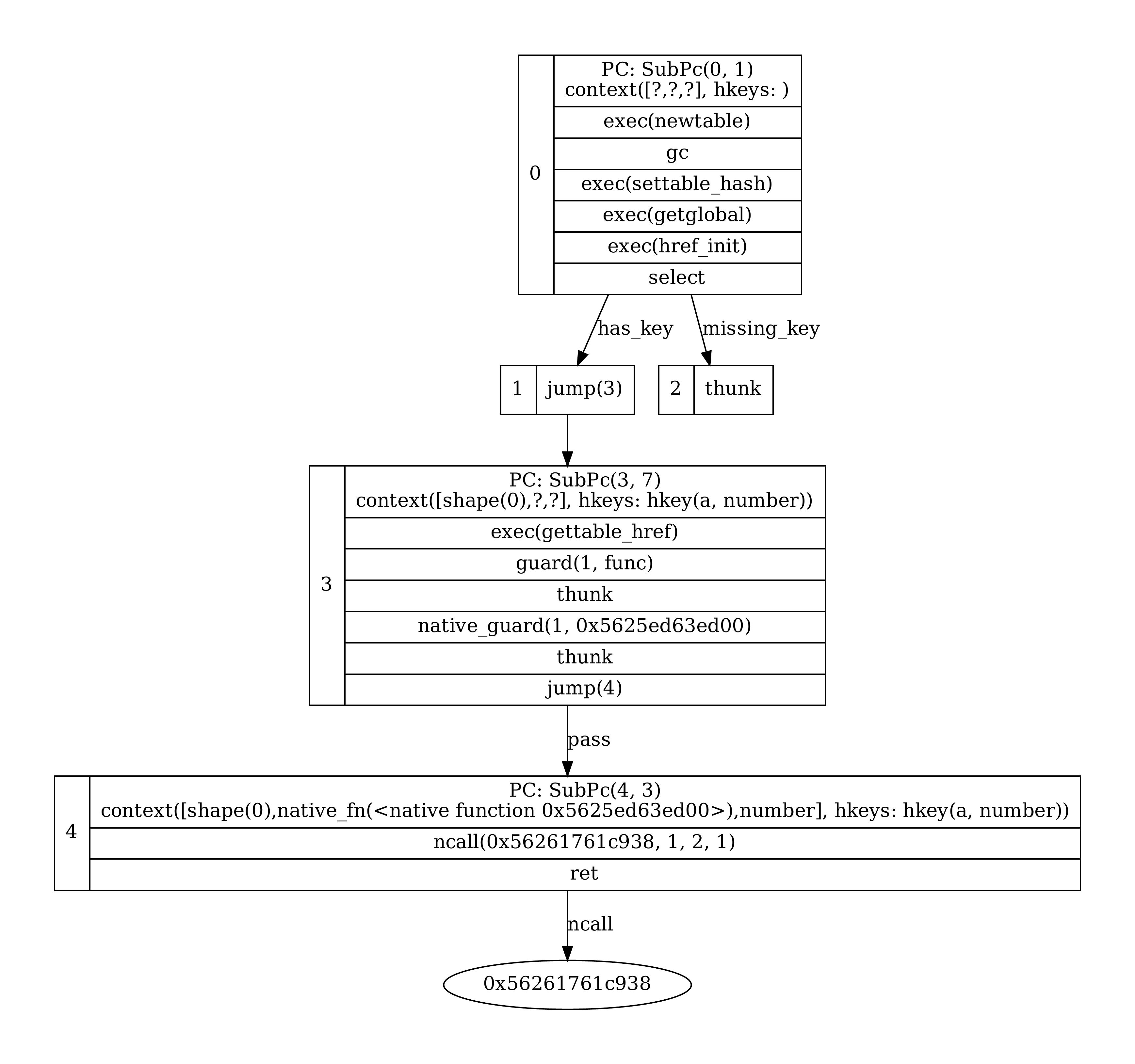
LBBV IR for
local t = {} t.a = 1 print(t.a).gettable_hrefdoesO(1)access with the hash witness index that was initialized byhref_init, and the stack slot containing
I did slightly tweak the LuaJIT scheme, adding a runtime “hash witness” table that is populated with the dynamic index of the key instead of including a constant index based on the first observed key index; the idea was that animal.age might be at different indexes even for subclasses because the hashmap storage resized based on different number of keys, and so initializing the offset the first time you see the key in each function would maintain the desired behavior. The hash witness table also includes a “table epoch”: like the shape transitions, when Lunacy sets the key on a table and can’t prove via static information that the value stays the same type, it increments a monotonic epoch counter, and the initial value of that epoch counter is saved when we initialize the hash witness entry. The epoch is needed in order to catch invalidation of table keys, where t.a = 1; t[dynamic] = "string"; t.a + 1 can’t assume that t.a stayed a string, and we must emit a guard that if t.epoch != witness[0].epoch: bail; success to verify the table stays the same. If the epoch increments, because the table had a new key added, we can do an “epoch repair” operation which do a full check that the value is still the expected type and either update the witness epoch value to the new table epoch now that we’re sure it’s still safe, or fallback to compiling a new block with the newly observed type.
But Lunacy now instead just uses IndexMap to implement the hash part of Lua tables, which have stable indexes based off insertion order, and removes the issue of indexes potentially being unstable based off resizing; I will probably remove the index from the witness and emit the constant index in the JIT directly, which will remove one data-dependent load from table property accesses while only introducing a few redundant blocks. The epoch scheme may also not be needed once I move to a better value representation (NuN boxing) which would be able to check the types of values in a single instruction, and so be as simple as our epoch guard is.
JIT IR for:
local function say(animal) print(animal.name .. " is ", animal.age, "years old") if animal.barks ~= nil then print("bowwow") end end. Despite calling it withlocal dog = {name = "Fido", age = 5, barks = "a lot"}andlocal cat = {name = "Mittens", age = 3, meows = "sometimes"}, the first
The other wrinkle with doing table shape optimization is around aliasing. If you have x.a = 1; y.a = "string"; x.a + 1, even though you never saw a store invalidate x.a it may now have the wrong type if x == y. The initial thing Lunacy was doing was just emit the epoch guard on every table access to catch these types of aliasing hazards; I eventually discovered the PyPy does a “type-based aliasing optimization”, where you can infer that y.b = "string" can’t invalidate x.a, because they’re different keys or different types - V8 is likewise able to do the same thing based on two variables having different know shapes I believe. With this we’re able to elide a lot of redundant epoch guards. Next up I want to try implementing caching of table property values in registers in the JIT, in order to remove redundant loads and perform store-to-load forwarding. Ideally this would allow code like t.a = t.a + 1 to stay entirely in a register without needing to touch memory inside a hot loop. This likewise has aliasing hazards like we had above for type stability, where print(other.a) potentially may observe the delayed store to t.a if other == t: I need to mess around to see how actually feasible this is, and how often these kinds of aliasing hazards would negatively affect benchmarks.
Performance
It’s not great?
Summary
./target/unsafe/bench nbody.bin 10 ran
1.01 ± 0.02 times faster than lua5.1 bench.lua -- lua_benchmarking/benchmarks/nbody/bench 10
1.11 ± 0.02 times faster than ./target/release/bench nbody.bin 10
2.77 ± 0.04 times faster than ./target/interpreter/release/bench nbody.bin 10
Summary
lua5.1 bench.lua -- lua_benchmarking/benchmarks/life/bench 1000 ran
1.66 ± 0.07 times faster than ./target/unsafe/bench life.bin 1000
2.03 ± 0.06 times faster than ./target/release/bench life.bin 1000
2.62 ± 0.05 times faster than ./target/interpreter/release/bench life.bin 1000
Currently, Lunacy runs about the same speed as PUC Lua 5.1 on nbody. nbody is heavy on table property accesses, and so we sure would hope we do better than PUC Lua, which will do actually-for-real hashmap lookups each time. Other benchmarks are a bit slower. This is very modest performance - but it is in fact occasionally faster than vanilla Lua, which was my initial end goal and I consider an achievement.
More notably, Lunacy’s interpreter-only mode is about 2.75x slower than Lua, which means the JIT does actually work in being substantially faster than the interpreter, which was my second big goal!
Why is it slower? Profiling is difficult, but it appears to be a mix of:
-
Our value representation is bad, and is literally just a Rust enum. Lunacy doesn’t do any pointer tagging, NaN boxing, or (the goal) NuN boxing currently - so our values are 2x more bytes than they ideally would be, which makes everything slower and precludes trying to keep them in registers as each value would consume two of them.
-
The LBBV specialization is kinda slow (~20% of runtime), in particular because the hash slot specialization creates a lot of thunks despite many of them being immediately forced. It is probably possible to avoid repeatedly switching back and forth between running and compiling for some of those thunks.
-
Likewise, the LBBV specialization clones a bunch of contexts and coroutines everywhere, and uses a lot of HashMaps. These can probably be optimized a lot as well to bring down the 20% overhead number.
-
The table hash slot specialization does a full hashmap lookup to initialize the hash witness index, and needs to load the index from the hash witness for accesses.
-
Lunacy doesn’t implement the function entrypoint specialization described in the sequel paper to LBBV, which means each function has no known types at its entrypoint again - and so has to re-initialize hash witnesses with the slow hashmap lookup. Oops! Performing entrypoint specialization with the continuation specialization for return values as well requires being able to invalidate continuations in the JIT, which is unfortunately kind of complicated.
-
Some of the residual operations which aren’t easy to implement in assembly (because they e.g. call Rust methods) are implemented by emitting calls to
JitHelperfunctions. These calls require shuffling values into ABI registers and can’t bake constants into the assembly, instead needing them to be passed as arguments. This isn’t actually a big percentage of wallclock time but it still feels bad.
And, of course, the big caveat of I’m mostly doing this as a fun side-project, and so haven’t been focusing on actual Lua feature compatibility in favor of doing neat JIT things. Notably, Lunacy doesn’t actually implement metatables yet, although I will need to implement them soon in order to run more benchmarks. Likewise it’s missing a couple bytecode operations, and there’s a decent amount of codepaths in existing bytecode operations that are unimplemented!(). I only recently bothered to even implement a basic mark-and-sweep garbage collector, and was relying on Rc<T> for garbage collection up until then.
Overall however, I’m very happy with the current progress on Lunacy. I’ve wanted to write a “real” JIT compiler for an interpreter for a while now, so it’s great to finally get around to it and reach the point I can get some ok-ish times on benchmarks.